
In this paper, recently published in the journal Ophthalmology, Yue Wu and his co-authors developed a unique method for training a model to identify the retinal layers on optical coherence tomography images, with the key feature that the model works successfully on optical coherence tomography (OCT) images from a different OCT device than the one that was used to obtain the training data. Although the field of deep learning image analysis is rapidly advancing, one major roadblock is the problem of domain shift, where models trained on a particular dataset may experience significant performance degradation when applied to slightly different datasets from different hospitals, imaging protocols, or device manufacturers.
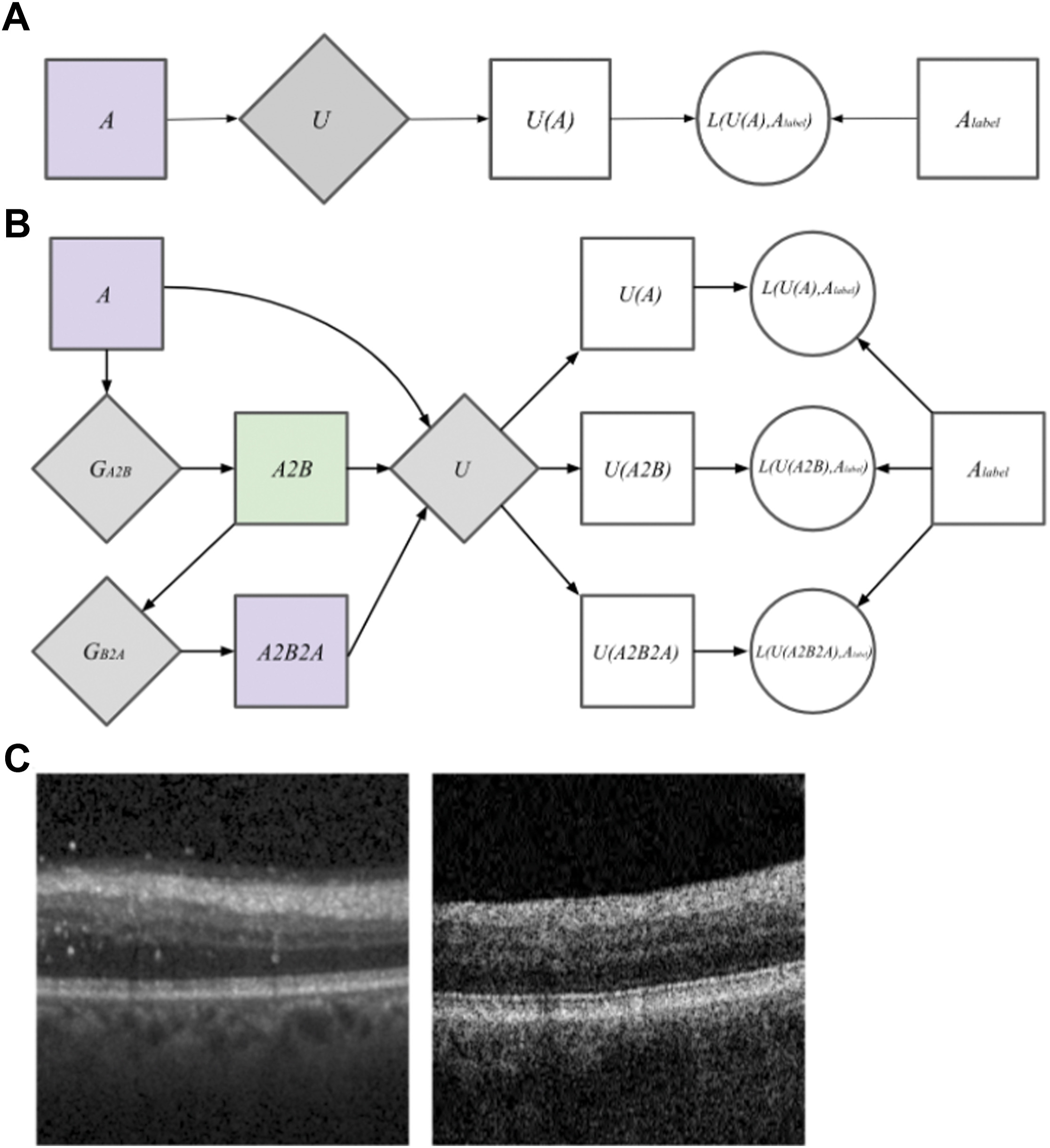
This segmentation model, called GANSeg, was able to segment OCT B-scan images from a Topcon 1000 OCT machine in a completely unsupervised fashion, even though the only labeled data it had access to was from a Heidelberg Spectralis OCT machine. The authors used a generative adversarial network (GAN) in combination with a supervised U-net model to achieve this unsupervised cross-domain learning. GANSeg had access to only raw, unlabeled Topcon 1000 B-scans during training, which helped the GAN component of GANSeg learn the Topcon 1000 style so that it could be applied to the Heidelberg scans. In this way, the GAN component augmented the dataset by pairing Heidelberg labels with Heidelberg scans in the style of Topcon 1000, thereby allowing the U-net segmentation model to perform well on both Heidelberg and Topcon 1000 styles. GANSeg performed as well in terms of Dice score as human graders for the held-out test Heidelberg B-scans, achieving Dice scores ranging between 70% and 100%. for the different retinal layers. The authors also trained a U-Net on only Heidelberg images to serve as a baseline comparison, and this model was not able to perform as well as GANSeg on the images from the Topcon device.
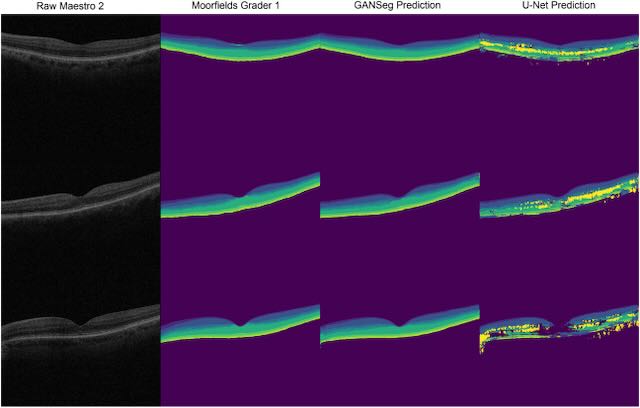
These results were exciting, demonstrating the potential to address a recurring limitation related to working with images form different imaging devices, and greatly increasing the generalizability of deep learning algorithms for supervised tasks such as classification and segmentation.
Wu Y, Olvera-Barrios A, Yanagihara R, Kung TH, Lu R, Leung I, Mishra AV, Nussinovitch H, Grimaldi G, Blazes M, Lee CS, Egan C, Tufail A, Lee AY. Training Deep Learning Models to Work on Multiple Devices by Cross-Domain Learning with No Additional Annotations. Ophthalmology. 2023 Feb;130(2):213-222.